
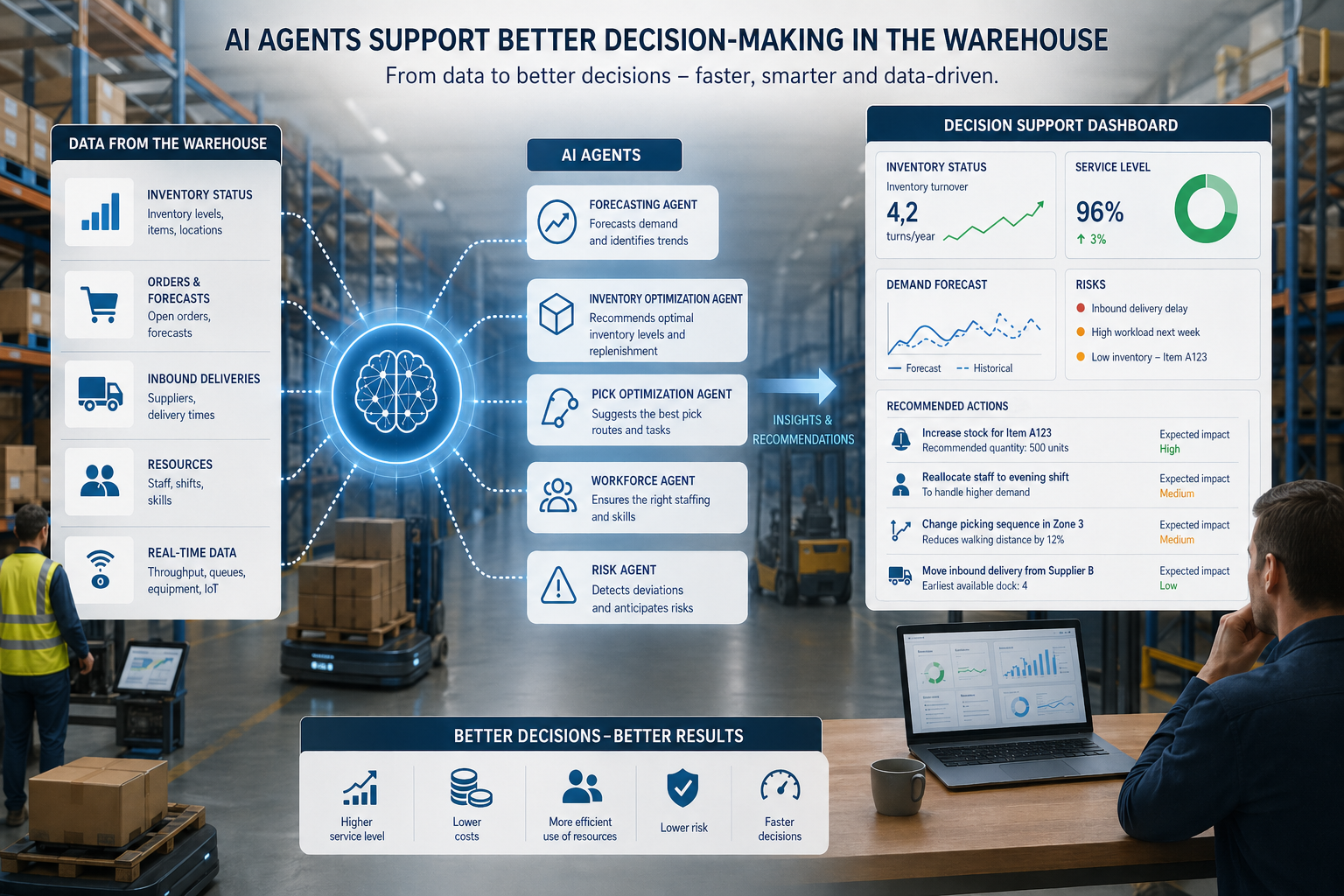
When warehouse AI moves from recommending to deciding, the hardest question is not technical. It is organizational.
It is early Tuesday morning and the afternoon shift is still hours away. No supervisor has flagged anything. No alert has been sent. But somewhere inside your warehouse management system, an AI agent has already decided that the staffing plan for the next six hours is wrong. It has recalculated the labour requirement, identified a shortfall of four people, and posted gig work assignments to an integrated staffing platform. Candidates are being notified right now.
You did not ask it to do that. You did not approve it. You may not even know it happened until you check the audit log.
This is not a hypothetical. Systems like this are being deployed today. And they raise a question that is more important than any of the technical ones: how much do you actually trust your AI agent, and how do you know when that trust is warranted?
Two ways to get this wrong
There is a common assumption that the risk with agentic AI in warehouse operations is that the system will act incorrectly, and that the solution is to keep a human in the loop on every decision. That assumption is half right.
Yes, an agent can make wrong calls. But the opposite failure is just as real and far less discussed. Organizations that keep humans in the loop on decisions the agent handles better than people do are not being cautious. They are paying a cost: slower response times, inconsistent outcomes, and the continued drain on supervisor attention that agentic AI was supposed to relieve.
There are two distinct failure modes, and they pull in opposite directions. Giving the agent too much autonomy too soon creates operational risk. Giving it too little means you have spent significant money on a system you do not actually trust enough to use. Both are expensive. Both are avoidable.
The question is not whether to trust the agent. It is how much trust, in which domains, under what conditions, backed by what governance.
The bias nobody talks about
Research on human interaction with automated systems has consistently found something counterintuitive: people are more likely to overtrust automation than to undertrust it. This is called automation bias, and it shows up in aviation, medical diagnostics, financial trading, and increasingly in logistics operations.
In practice, automation bias in a warehouse context looks like this. The AI agent recommends a replenishment action. The operator sees the recommendation on screen. The recommendation looks plausible. The operator confirms it without checking the underlying data, because checking takes effort and the system has been right eighty times in a row. The eighty-first time, the system is wrong, and the operator does not catch it because they have stopped looking critically.
The deeper irony is that this risk increases as the system gets better. The better your agent performs, the more tempting it becomes to approve its outputs without scrutiny. And the less scrutiny humans apply, the less prepared they are to catch the cases where the system fails in ways that are genuinely hard to anticipate.
The goal is not a workforce that trusts the AI agent. It is a workforce that trusts it accurately, which means understanding both what it is good at and where it can fail.
This requires deliberate organizational design. It does not happen on its own.
Who owns the decision when the agent is wrong?
This question makes people uncomfortable, which is usually a sign it is worth asking.
When a supervisor makes a poor labour call that causes a throughput failure on a peak day, the accountability is clear. When an AI agent makes the same call autonomously, the picture gets blurry fast. Was it a configuration problem? A data quality issue? Did the agent encounter a situation outside the range of conditions it was designed for? Did someone approve the guardrails that turned out to be inadequate?
In most early agentic deployments, accountability is distributed across the vendor, the implementation team, the operations manager who accepted the configuration, and the IT function that owns the integration. In practice, that often means accountability belongs to no one in particular, which is a different and worse problem than getting the decision wrong in the first place.
This matters because accountability is not just a legal or governance concern. It is a prerequisite for learning. If no one owns the outcome of an agent’s decision, no one has the incentive to investigate what went wrong and redesign the system to prevent it happening again. The operation loses the feedback loop that makes continuous improvement possible.
Before you expand the autonomy of any agentic system, you need a clear answer to three questions. Who is responsible for defining the agent’s objective and constraints? Who reviews the agent’s decision log and acts on anomalies? And who has the authority and obligation to pull the agent back to a more supervised mode when something does not look right?
If you cannot answer all three, you are not ready to run the agent at the autonomy level you are considering.
Trust is built the same way with agents as with people
There is a useful analogy here that most organisations overlook.
When a skilled but new warehouse employee joins an operation, nobody hands them full decision authority on day one. They learn the flow. They work alongside experienced people. They make decisions in lower-stakes areas first. They build a track record. As that track record develops, their autonomy expands, in direct proportion to demonstrated reliability in progressively more complex situations.
The same logic applies to AI agents, and the organisations that deploy them most effectively tend to follow an almost identical path.
You start with a supervised mode, where the agent makes recommendations and humans execute them. You measure the agent’s recommendation quality against actual outcomes. You identify the domains where the agent is consistently right, and the conditions where it struggles. Then you expand autonomy selectively, beginning with the decisions that are high frequency, low stakes, and well within the range of situations the agent handles reliably.
Over time, the agent’s sphere of autonomous action grows, but it grows based on evidence, not on vendor assurances or executive enthusiasm for the technology. And crucially, certain decisions stay in human hands permanently, not because the agent could not theoretically handle them, but because the consequences of getting them wrong, or of being unable to explain why a decision was made, require human judgment and accountability that technology cannot substitute for. This challenge is explored further in why warehouse automation investments fail.
Designing for the right level of autonomy
The practical work of getting this right happens at the design stage, before deployment, and revisits regularly as the operation evolves.
Four elements matter most.
Objective clarity. The agent needs an unambiguous objective and explicit constraints. Throughput is not an objective. Maintaining a pick accuracy rate above 99.6 percent while achieving a throughput target of X units per hour within a labour budget of Y hours, with escalation triggered when any constraint is at risk of breach, is an objective. The specificity is not bureaucratic. It is what allows the agent to operate within boundaries you have actually thought through.
Calibrated escalation thresholds. Not every decision should be made autonomously, and not every exception should require human resolution. The design question is where the boundary sits. Decisions that are routine, reversible, and well within the agent’s demonstrated competence should be autonomous. Decisions that are novel, irreversible, or that affect external stakeholders in ways not covered by the agent’s training should escalate. That threshold is not fixed. It should be reviewed and adjusted as the agent builds its track record.
Transparent audit trails. If the operations team cannot see what the agent did, why it did it, and what the outcome was, they cannot maintain accurate trust calibration. Transparency is not a nice-to-have feature. It is the mechanism by which humans stay appropriately engaged rather than drifting into passive acceptance or uninformed suspicion.
Regular trust recalibration. Seasonal peaks, product range changes, new customers, and altered workflows all change the distribution of situations the agent encounters. A system that performs reliably in normal conditions can behave unexpectedly when the operation shifts significantly. Scheduled reviews of agent performance across changing conditions are not optional maintenance. They are the core of responsible agentic governance.
The autonomy spectrum is not a destination
One of the more seductive ideas in conversations about agentic AI is that the goal is a fully autonomous operation, with the agent handling everything and humans stepping back into a purely strategic role. It is a compelling image. It is also, for most warehouse operations, the wrong goal to anchor on.
The question of how much autonomy an agent should have does not have a permanent answer. It has a current answer, based on the agent’s demonstrated performance, the nature of the decisions involved, the consequences of errors in those decisions, and the organisation’s ability to monitor, interpret, and act on what the agent is doing.
The right level of autonomy for an AI agent is not the maximum level it can theoretically handle. It is the level at which the operation can genuinely trust it, monitor it, and recover from its mistakes.
That level will change over time, as the agent builds a track record and the organisation develops the skills to work alongside it effectively. Getting to full operational trust in the high-stakes decisions is a multi-year journey for most organisations, and that is not a failure of ambition. It is what responsible deployment of consequential technology actually looks like.
The organisations that will capture the most value from agentic AI in the next several years are not the ones that grant the most autonomy the fastest. They are the ones that build trust deliberately, expand autonomy on the basis of evidence, and design governance systems that keep humans genuinely engaged rather than passively watching a system they no longer understand.
That is harder than deploying the technology. It is also the part that determines whether the technology actually works.
The same principle holds beyond agentic systems specifically. Whatever the technology, the work of building trust, transparency, and genuinely engaged operators does not end at deployment, and the cost of treating it as finished is well documented in The Automation Project Ends at Go Live. That Is the Problem.


